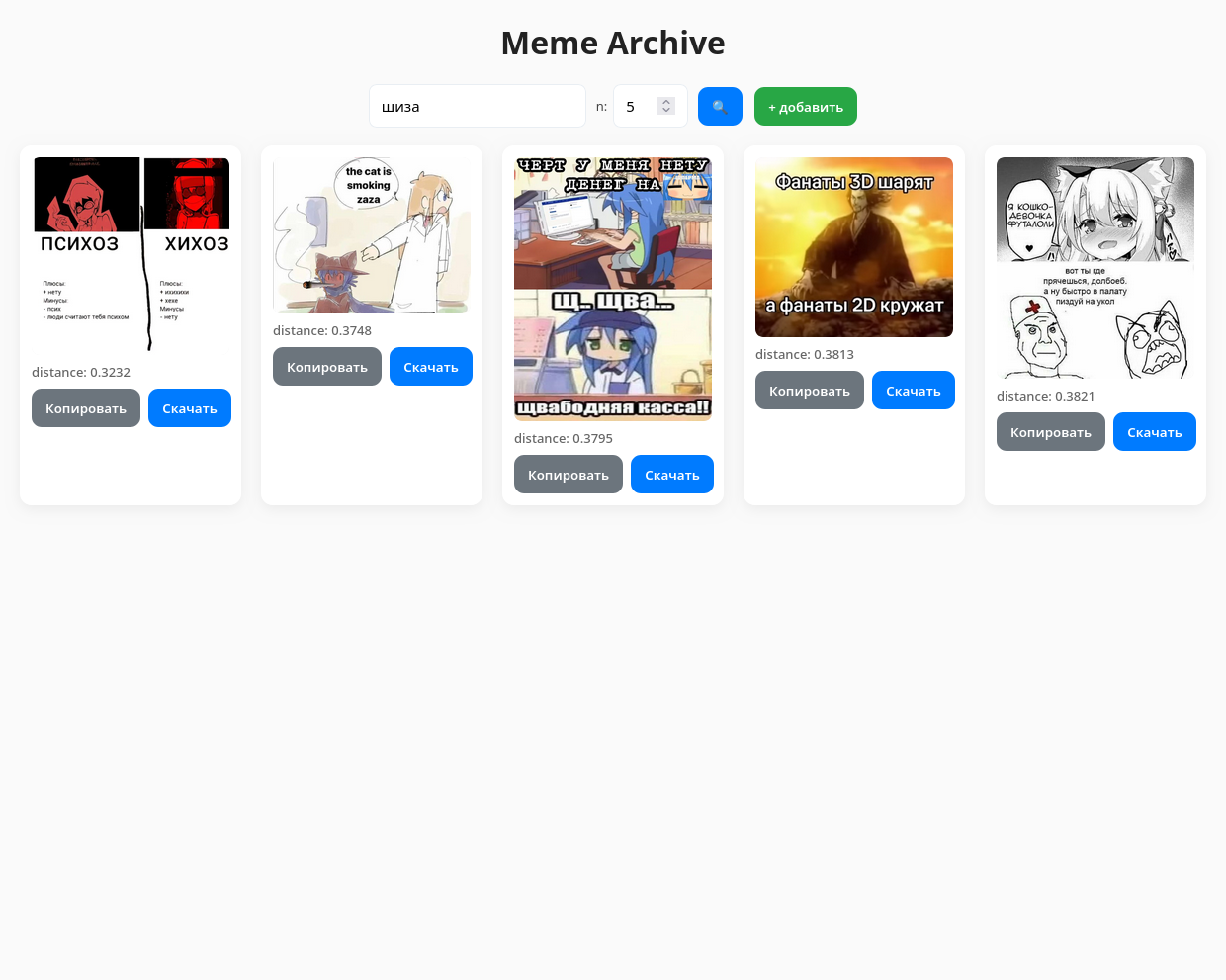
Векторный поиск картинок(мемов)
У меня есть около 600 мемов. Когда нужно скинуть какой-то конкретный другу — начинается перебирания всех картинок в поисках той самой. «проблем современного человека».
Но я же программист! Решил автоматизировать этот процесс и сделать meme archive с поиском по картинкам. Изначальная идея была простой:
- Преобразовывать картинки в векторы (embeddings) через ИИ
- Делать то же самое с текстовыми запросами
- Искать совпадения через векторную БД
Но тут начались проблемы. Не нашёл бесплатного API для моделей типа BLIP, которые работают в едином векторном пространстве для текста и изображений. Запускать локально на ПК тоже не хотелось — долго и требует ресурсов.
Пришлось идти по тупому пути:
- Использовал бесплатный API Google AI Studio (да, он не работает в РФ, как и большинство сервисов)
- Модель
gemini-flash-lite-latestгенерирует текстовое описание для каждого мема - Для этих описаний создаю эмбеддинги
- Храню всё в векторной БД Chroma